




An LSTM-based Startup Name Generator
Update 2018-12-02
This repository still exists, but it is now a proper Python package, not just a script anymore. The motivation described in this post is still true, but the usage guide is outdated. See the repository for the updated documentation.
Summary
In this post I present a Python script that automatically generates suggestions for startup names. You feed it a text corpus with a certain theme, e.g. a Celtic text, and it then outputs similar sounding suggestions. An example call looks like this:
./generate.py -n 10 -t 1.2 -m models/gallic_500epochs.h5 wordlists/gallic.txt --suffix Software
Output:
=======
Ercos Software
Riuri Software
Palia Software
Critim Software
Arios Software
Veduos Software
Eigla Software
Isbanos Software
Edorio Software
Emmos Software
I applied the script to “normal” texts in German, English, and French, and then experimented with corpora of Pokemon names, death metal song lyrics, and J.R.R. Tolkien’s Black Speech, the language of Mordor.
I’ve made a few longer lists of sample proposals available here.
You can find the code, all the text corpora I’ve used, and some pre-computed models in my GitHub repo:
https://github.com/AlexEngelhardt/startup-name-generator
My need for automatic company names
Recently, an associate and I started work on founding a software development company. The one thing we struggled most with was to come up with a good name. It has to sound good, be memorable, and the domain should still be available. Both of us like certain themes, e.g. words from Celtic languages. Sadly, most actual celtic words were already in use. We’d come up with a nice name every one or two days, only to find out that there’s an HR company and a ski model with that exact name.
We needed a larger number of candidate names, and manual selection took too long. I came up with an idea for a solution: Create a neural network and have it generate new, artificial words that hopefully are not yet in use by other companies. You’d feed it a corpus of sample words in a certain style you like. For example, Celtic songs, or a Greek dictionary, or even a list of Pokemon. If you train the model on the character-level text, it should pick up the peculiarities of the text (the “language”) and then be able to sample new similar sounding words.
A famous blog post by Andrej Karpathy provided me with the necessary knowledge and the confidence that this is a realistic idea. In his post, he uses recurrent neural networks (RNNs) to generate Shakespeare text, Wikipedia articles, and (sadly, non-functioning) source code. Thus, my goal of generating single words should not be a big problem.
Data preprocessing
For input data, I just built a corpus by using raw, copy-pasted text that sometimes included numbers and other symbols. A preprocessing was definitely necessary. I first stripped out all non-letter characters (keeping language-specific letters such as German umlauts). Then, I split the text up in words and reduced the corpus to keep only unique words, i.e. one copy of each word. I figured this step was reasonable since I did not want the model to learn the most common words, but instead to get an understanding of the entire corpus’ structure.
After this, most text corpora ended up as a list of 1000 to 2000 words.
The RNN architecture
The question which type of neural network to use was easily answered. Recurrent neural networks can model language particularly well, and were the appropriate type for this task of word generation.
However, to my knowledge, finding the ‘perfect’ RNN architecture is still somewhat of a black art. Questions like how many layers, how many units, and how many epochs have no definite answer, but rely on experience, intuition, and sometimes just brute force.
I wanted a model that was as complex as necessary, but as simple as possible. This would save training time. After some experiments, I settled for a two-layer LSTM 50 units each, training it for 500 epochs and a batch size of 64 words. The words this model outputs sound good enough that I didn’t put any more energy in fine-tuning the architecture.
Sampling temperature
The RNN generates a new name character by character. In particular, at any given step, it does not just output a character, but the distribution for the next character. This allows us to pick the letter with the highest probability, or sample from the provided distribution.
A nice touch I found is to vary the temperature of the sampling procedure. The temperature is a parameter that adapts the weights to sample from. The “standard” temperature 1 does not change the weights. For a low temperature, trending towards zero, the sampling becomes less random and the letter corresponding to the maximum weight is chosen almost always. The other extreme, a large temperature trending towards infinity, will adjust the weights to a uniform distribution, representing total randomness. You can lower the temperature to get more conservative samples, or raise it to generate more random words. For actual text sampling, a temperature below 1 might be appropriate, but since I wanted new words, a higher temperature seemed better.
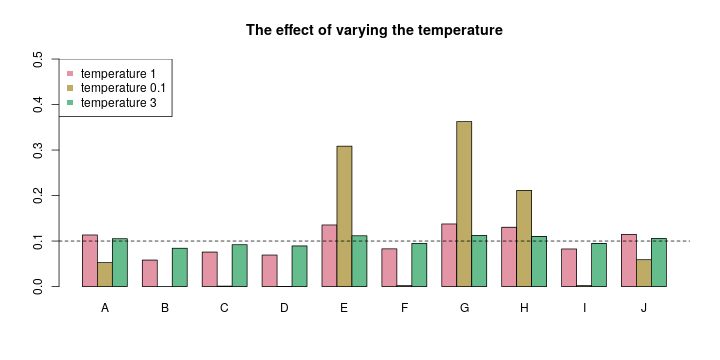
In the image above, imagine we want to sample one letter from A, B, …, J. Your RNN might output the weights represented by the red bars. You’d slightly favor A, E, G, H, and J there. Now if you transform these weights with a very cold temperature (see the yellow-ish bars), your model gets more conservative, sticking to the argmax letter(s). In this case, you’d most likely get one letter of E, G, and H. If you lower the temperature even further, your sampling will always return the argmax letter, in this case, a G.
Alternatively, you can raise the temperature. In the image above, I plotted green bars, representing a transformation applied with a temperature of 3. You can still see the same preferences for E, G, and H, but the magnitude of the differences is much lower now, resulting in a more random sampling, and consecutively, in more random names. The extreme choice of a temperature approaching infinity would result in a totally random sampling, which then would make all your RNN training useless, of course. There is a sweet spot for the temperature somewhere, which you have to discover by trial-and-error.
Example calls and sample output
Call the script with the -h parameter to have it print an overview of all
possible parameters. The following command trains an LSTM model on the
wordlists/english.txt corpus for 500 epochs (-e 500), saves the model (-s)
to models/english_500epochs.h5, and then samples 10 company names (-n 10)
with a higher, more random temperature of 1.2 (-t 1.2), and finally appends
the word “Software” (--suffix) to the names. While training, I like to pass
the -v argument to run in verbose mode. Then, the model prints some extra
information as well as a few sample generated words each 10 epochs:
./generate.py -v -e 500 -n 10 -t 1.2 -s models/english_500epochs.h5 wordlists/english.txt --suffix Software
My call returned this output:
Officers Software
Ahips Software
Appearing Software
Introduce Software
Using Software
Alarmed Software
Interettint Software
Entwrite Software
Understood Software
Aspemardan Software
Some other fine name suggestions I encountered, and are too good not to share:
- Indeed (see, it works!)
- Unifart (I dare you!)
- Lyston
- Alton
- Rocking
- Moor
- Purrs
- Ture
- Exace
- Overheader
After you stored the model (with the -s option), word generation is quicker
when you load instead of re-compute the model (using the -m argument):
./generate.py -n 20 -t 1.2 -m models/english_500epochs.h5 wordlists/english.txt --suffix Software
Input corpora used
I collected a text each in German, English and French, just to have some realistic sounding words and gauge how well the model has learned the corpus structure.
However, most of my time was then spent on more fun corpora. Below, I’ll briefly
describe them and also show some randomly sampled output for the (totally not
cherry-picked) generated words. I also uploaded these corpora to the project’s
GitHub repository,
in the wordlists subdirectory.
Celtic
My main target was a Celtic sounding name. Therefore, I first created a corpus of two parts (browse it here): first, a Gallic dictionary, and second, selected song lyrics by the swiss band Eluveitie. They write in the Gaulish language, which reads very pleasantly and makes for good startup names in our opinion.
Lucia
Reuoriosi
Iacca
Helvetia
Eburo
Ectros
Uxopeilos
Etacos
Neuniamins
Nhellos
Pokemon
I also wanted to feed the model a list of all Pokemon, and then generate a list of new Pokemon-themed names.
Grubbin
Agsharon
Oricorina
Erskeur
Electrode
Ervivare
Unfeon
Whinx
Onterdas
Cagbanitl
Tolkien’s Black Speech
J.R.R. Tolkien’s Black Speech, the language of the Orcs, was a just-for-fun experiment (wordlist here). It would be too outlandish for a company name, but nonetheless an interesting sounding corpus.
Aratani
Arau
Ushtarak
Ishi
Kakok
Ulig
Ruga
Arau
Lakan
Udaneg
Death metal lyrics
As a metal fan, I also wanted to see what happens if the training data becomes song lyrics. I used lyrics by the Polish death metal band Behemoth, because the songs are filled with occult-sounding words (wordlist here).
Artered
Unlieling
Undewfions
Archon
Unleash
Architer
Archaror
Lament
Unionih
Lacerate
You can add anything from “Enterprises” to “Labs” as a suffix to your company name. I found a long list of possible suffixes here.