




Preparing for the Cloudera Exam CCA175: Spark and Hadoop Developer
I am preparing to take the Cloudera exam to become a certified Spark and Hadoop developer. The official trainings are quite pricy, so I am preparing on my own. This blog series follows my journey.
My definition of “ready for the exam” is:
- Make sure to have internalized all the blog posts in the next section
- Be able to solve the example problems provided on itversity
- Additionally, the exam allows you to access some documentation online, namely the list at the bottom of the exam home page. Familiarize yourself with the necessary sections there (Sqoop, Spark, Flume, Python, and Scala).
The blog posts
I tried to assemble a structured and concise summary of all the skills and concepts required for the exam here. The material is organized into a series of blog posts.
I’ll list all the respective blog posts below. The remainder of this article is about how I arrived at that list.
- Using Sqoop to move data between HDFS and MySQL
- Load data into and out of HDFS using the Hadoop File System commands
- Spark Core with Python
- Spark SQL with Python
- Flume
- Spark Streaming
- Scala
- Command-line options for spark-submit
Addendum: After my exam
This subsection briefly describes my exam contents and experiences. I took the exam on 14 October 2017.
- I had no “fill in the blanks” template files in my exam, just a problem description with a path to the files, and a specified path and format for the output files.
- I was given nine questions:
- Two straightforward Sqoop questions (one import and one export, where the MySQL table was already specified and empty)
- One question to transform data stored as JSON into an Avro file
- One question to transform a table from the metastore into a parquet file with a certain compression codec (it was snappy, I think).
- Five Spark questions, each of which were a simple load, transform, and store process. Questions included a column subsetting, a filtering, a concatenating of two character columns, and one join of two tables. Note that if the solution path is given as
/user/cert/problem5/solution, the solution files have to go directly in this directory. Do not create a subdirectory under thesolutionfolder.
The Syllabus
Unfortunately, Cloudera is somewhat secretive about the exam contents. In terms of official preparation, all I’ve found are the following two sources:
- The exam home page, of course. It has a video for one sample question, and a list of required skills. This list is detailed in some parts, but very vague in others. For example, one bullet point says “Process streaming data as it is loaded onto the cluster”, without mentioning the tool.
This page also specifies the cluster and the available software. Note that it comes with Spark 1.6, so Spark 2 won’t be available.
- The course contents of the corresponding Cloudera training. This page has a PDF with a list of course contents. These might be excessive, though.
Reviews by others taking the exam converge to the following structure:
- 2 easy Sqoop questions to import/export from MySQL to HDFS and back
- 3 easy Hive questions
- 1 easy Avro question
- 4 Spark questions, of which 2 were in Scala and 2 in Python. The tasks here seem to be fill-the-blank scripts.
However, the exam syllabus has changed in March 2017. The general focus has now concentrated on Spark, including Spark SQL and Spark Streaming. There is less MapReduce, and no more Hive or Impala (but Sqoop and Flume are still in there). This website provides a before-after table with nicely commented changes I’ll reproduce here:
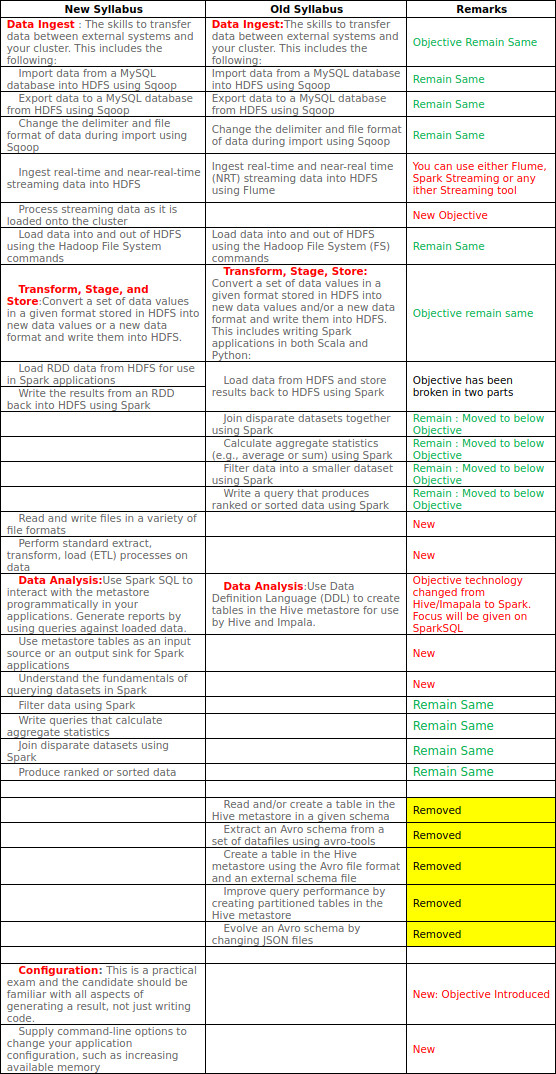
Now this table helps a lot! Avro was required earlier, but is no more. And the streaming data can be analyzed with either Flume or Spark Streaming. They also introduced a few new topics to watch out for.
Material
There are extensive tutorials on YouTube. Following these in their entirety would be useful at a later stage for your actual work, but maybe too much for just passing the exam.
I prepared using the Udemy courses by Frank Kane, specifically the following four, in this order:
- The Ultimate Hands-On Hadoop
- Taming Big Data with Apache Spark and Python
- Apache Spark 2.0 with Scala
- Taming Big Data with Spark Streaming and Scala
The courses normally cost over $100, but he currently provides heavy discounts on the courses on his website.
There are also O’Reilly books on Hadoop, Spark, Python and Scala which are an awesome comprehensive resource. These will be crucial for actually working with these tools, but probably not necessary for passing the exam.
Preparation
The questions all seem to be very basic, so there is no need to spend too much time learning each tool’s intricacies. In light of the passing score of 70%, I will apply the Pareto principle and register for the exam sooner rather than later.
This website gives a very nice mapping from “syllabus” to “skills required”, and I made heavy use of it in creating my study plan. He also provides a few sample problem scenarios there, which are very helpful to monitor your progress.
I’ll use the following hierarchical checklist to study, and check off sub-items as soon as I have a “good enough” grasp on each topic. If everything is checked, there are no more excuses!
I have a cheat sheet with brief commands for each bullet point, along with notes and explanations, in other blog posts linked to in the top of this post.
- Data Ingest
- Sqoop
- Import and export from MySQL
- vary HDFS field delimiter and file format
- Flume/Spark Streaming
- Ingest real-time and near-real-time streaming data into HDFS
- Process streaming data as it is loaded onto the cluster
- Hadoop FS commands to import and export data
- Sqoop
- Transform, Stage, and Store: Convert a set of data values in a given format stored in HDFS into new data values or a new data format and write them into HDFS.
- Use Spark to read in a HDFS file as an RDD and write it back (via Scala and Python)
- Read and write files in a variety of file formats
- Perform standard extract, transform, load (ETL) processes on data
- Data Analysis: Use Spark SQL to interact with the metastore programmatically in your applications. Generate reports by using queries against loaded data.
- Use metastore tables as an input source or an output sink for Spark applications
- Use Spark to filter, aggregate, join (between disparate sources), rank, and sort datasets
- Configuration:
spark-submitalong with command-line options to change your application configuration, such as increasing available memory