




The Hadoop ecosystem: An overview
I am diving into the world of Hadoop right now. This post is to serve me as a cheat sheet for the use of and connections between the many available tools in the Hadoop ecosystem.
I am following this udemy course on Hadoop. My notes are mainly based on that course and the book “Hadoop: The Definitive Guide” by Tom White.
Hadoop
- Hortonworks’ definition: “An open source software platform for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware.”
- It can run on an entire cluster instead of one PC
- “Distributed storage”: A data set is spread across multiple hard drives. If one of them burns down, the data is still reliably stored.
- “Distributed processing”: Hadoop can aggregate data using many CPUs in the cluster
- The storage is based on Google’s GFS, the processing on Google’s MapReduce
- With Hadoop, you can scale horizontally (i.e., add more nodes) instead of vertically (i.e., add more resources to a single PC)
- Core Hadoop consists of the basis HDFS (the distributed file system with redundancy), then on top YARN (the resource negotiator, i.e. the data processing scheduler), and as a last layer MapReduce (the programming model). All other tools of the ecosystem emerged over time and solve more specific problems. A Google image search for “Hadoop ecosystem” shows a few nice stacked diagrams or these other technologies. Also, this GitHub page is a great summary of all current technologies.
- The RHadoop toolkit allows you to work with Hadoop data from R
YARN
YARN stands for Yet Another Resource Negotiator. It was introduced in Hadoop 2, where the resource negotiation part was split out from MapReduce, so that alternatives to MapReduce (such as Spark and Tez) could be built on top of YARN. Where HDFS splits up the data storage across your cluster, YARN splits up the computation.
YARN will try to align worker nodes and storage nodes to run jobs as efficiently as possible. The resource manager spins up a MapReduce application. It first spawns an application master on some node that has capacity. The application master then requests additional nodes that run different application processes (which are usually Map or Reduce tasks).
Usually, you should not code against YARN directly. Instead, use one of the higher-level tools, for example Hive, to make your life easier.
Hive
Hive provides a SQL-like language for working on data stored on Hadoop-integrated systems. That is, it makes your HDFS-stored data look like a SQL database. Under the hood, it transforms the queries into efficient MapReduce or Spark jobs. Also, R and its RJDBC and/or RODBC packages can use Hive commands.
Pig
Pig is a platform for creating data processing programs that run on Hadoop. The corresponding scripting language is called Pig Latin, has a SQL-similar syntax, and it can perform MapReduce jobs. Without Pig, you would have to do more complex programming in Java. Pig then transforms your scripts into something that will run on MapReduce.
Hive vs. Pig
Both components solve similar problems; they make it easy to write MapReduce programs (easier than in Java, that is). Pig was created at Yahoo, Hive is originally from Facebook.
Spark
Spark is probably the most popular technology right now. It is similar to MapReduce. It sits on top of YARN or Mesos. You can write MapReduce queries in Python, Java or Scala (preferred). It’s very fast and reliable right now. It can handle SQL queries, handle Machine Learning algorithms across a cluster, and many more things.
Ambari
Ambari is a web-interface to view and control your Hadoop cluster. Ambari is the Hortonworks solution. Competing distributions (e.g. Cloudera) have other tools here. It “sits on top of everything”. It gives you a high-level view of your cluster, what’s running, what system you are using, what resources are available/in use.
Ambari can even be used to install Hadoop.
Zookeeper
Zookeeper is a coordinator. Many other tools rely on it. It can keep track of what node is up/down, which one is the master node, what workers are available, and many more things. Tools like HBase or Drill make use of Zookeeper to recover from failures during a task.
Things that can go wrong on your cluster include the master node crashing, a worker crashing (so its work needs to be redistributed), or network trouble, where a part of your cluster can’t see the rest of it anymore. In a distributed system, many many things can cause some sort of failure. Zookeeper sits on the side of your system and tries to maintain a consistent picture of state on your entire distributed system in a consistent manner.
It does so by creating a little distributed file system that any application on your system can write to or read from. It ensures consistency of this data, but it delegates the work of managing this information to the individual applications.
You’ll typically have more than one Zookeeper server (called an ensemble), so that one node failing won’t be a problem. The servers keep their information stored redundantly. All other applications then run a Zookeeper client that maintains a list of all servers.
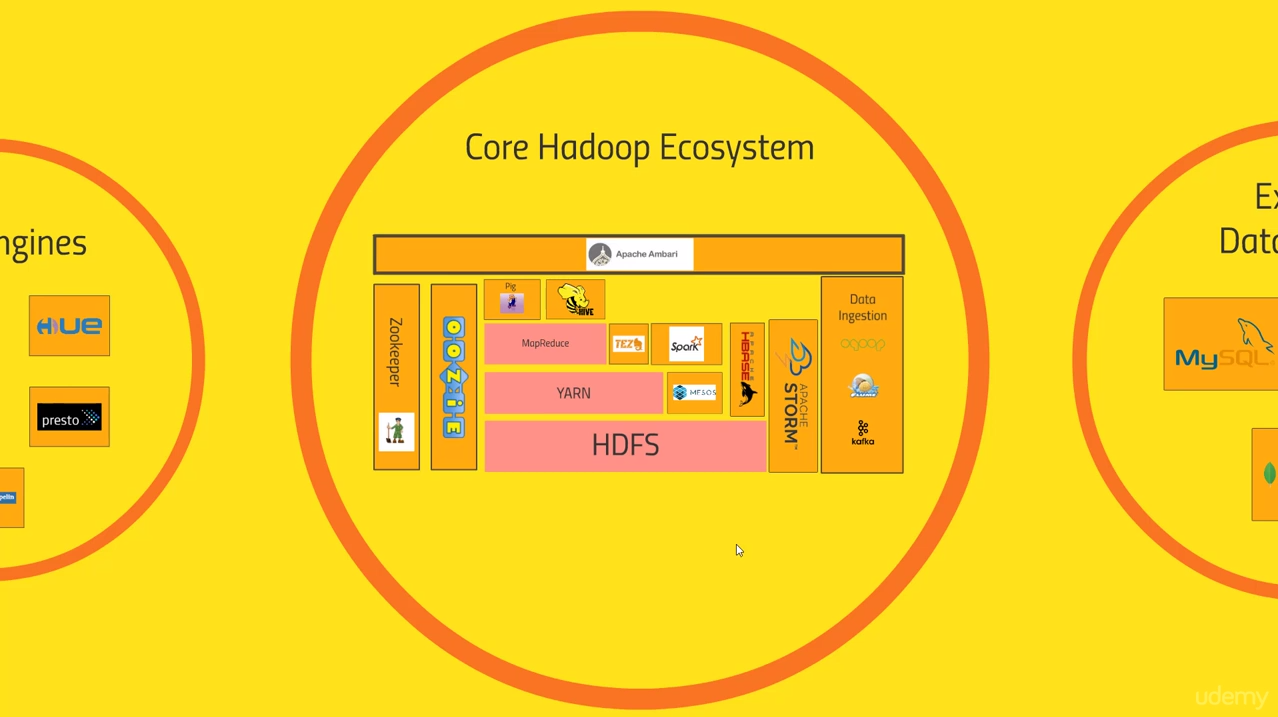
Misc other tools
- Mesos: Another resource negotiator, i.e. a YARN alternative. It originates from Twitter. While YARN is restricted to Hadoop tasks (e.g. MapReduce, Spark), Mesos is more general in scope and allocates resources for many other applications like web servers, small scripts, etc.
- TEZ: Similar to Spark. It sits on top of YARN and is often used with Hive on top. It can make your Hive, Pig, and MapReduce jobs a lot faster. It’s based on directed acyclic graphs (DAGs) to process distributed jobs more efficiently. To do this, Tez eliminates unnecessary steps, minimizes dependencies and runs certain subtasks in parallel. It is basically always a good idea to use Tez, it has no disadvantages and speeds up your code significantly.
- HBase: A NoSQL database. It sits on top of HDFS. This is the way to go if you want real-time read/write access to very large datasets. With HBase, you can expose your (maybe transformed by Spark or MapReduce) data to other systems.
- Storm: Process streaming data from sensors in real time. “Spark Streaming” does a similar thing, but Storm works on individual events instead of micro-batches. Spark seems like a better choice to me, because you’re not limited to Java (you can use Spark with Python, Scala, or even R), and because Spark has a lot of tools on top, such as the machine learning library (MLLib).
- Oozie: A tool for running and scheduling periodic Hadoop jobs on your cluster. You can also create a workflow of different Sqoop, MapReduce, Pig, Hive tasks and tie them together into one large workflow with interdependent results. The workflows are specified via XML, and are built by a directed acyclic graph, so Oozie will know which tasks can be started in parallel. Oozie also provides a web interface to monitor the progress and status of your workflows. You can schedule workflows like a UNIX cronjob, but they can also wait for external data to become available before they start running.
- Sqoop, Flume, Kafka: These are tools for data ingestion, i.e. getting data into your cluster/HDFS storage. Sqoop is a connector between your Hadoop database and a relational DB, and can also talk to ODBC/JDBC. For example, Sqoop can import data from MySQL to HDFS with a MapReduce job. Flume can transport weblogs (e.g. from many webservers) into your cluster, to be then analyzed by Storm or Spark streaming. Kafka is a bit more general, but solves a similar problem.
External data storage
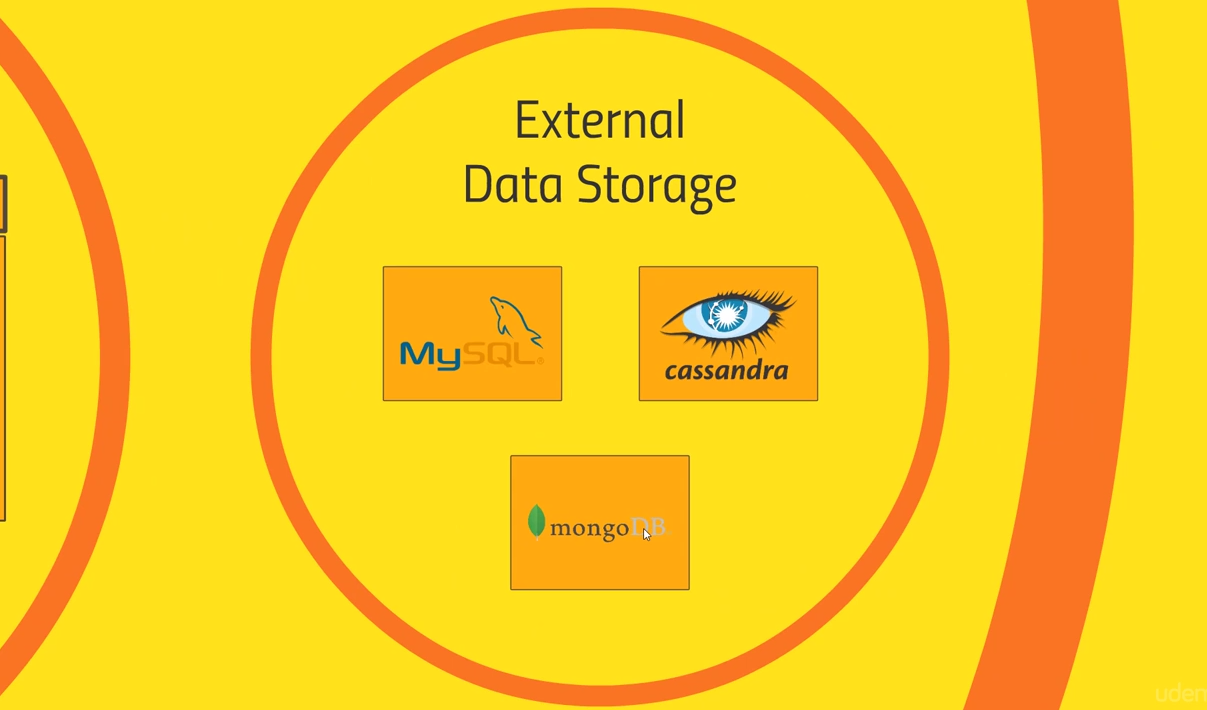
- MySQL: With sqoop, you can read and write from MySQL.
- Cassandra and MongoDB: Other NoSQL alternatives.
- HBase fits in here too, but technically is not “external”, but is a direct part of Hadoop
Query engines
External tools to interactively enter SQL queries. Hive is similar to these tools here.
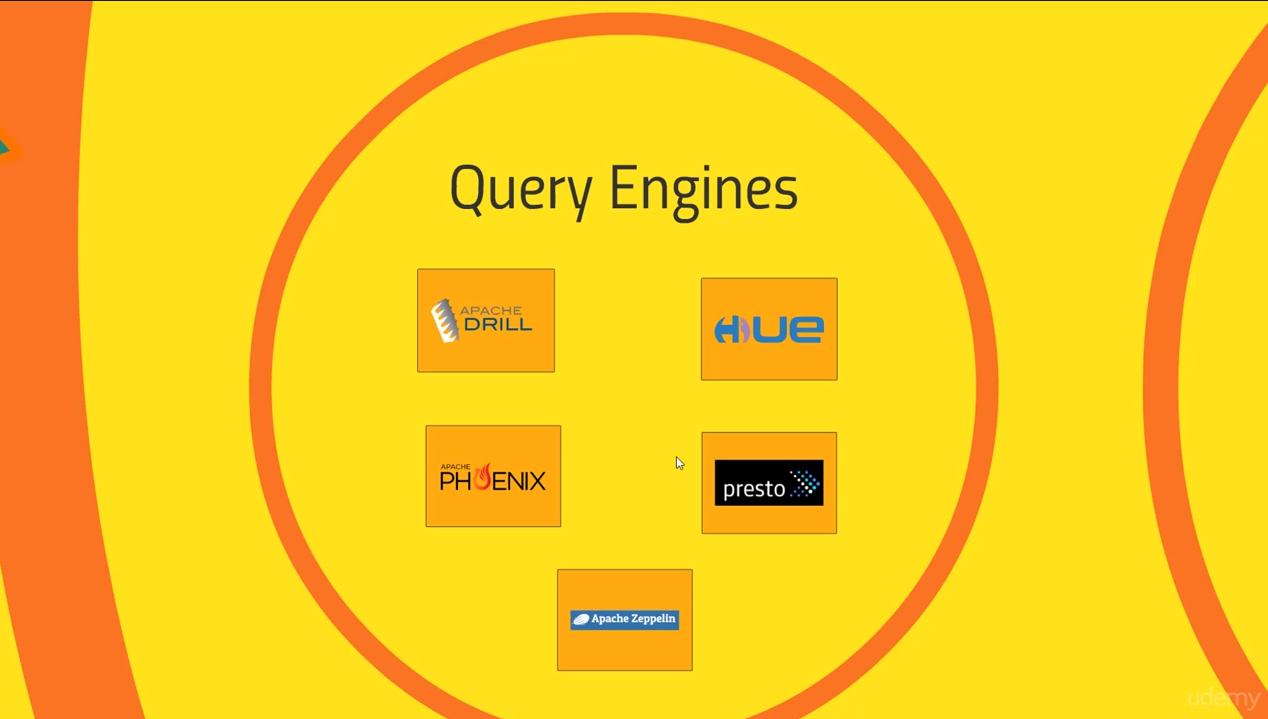
- Apache Drill: Write proper SQL queries to diverse data stores like S3, HDFS, or NoSQL databases (HBase, mongoDB) and unify these data sources into single SQL queries
- Apache Phoenix: This is similar to Drill, but it only works on HBase. It can guarantee relational DB behavior on a NoSQL database. It’s fast and low-latendcy, and has OLTP support. You can access Phoenix with tools like Pig to optimize the connection to HBase.
- Apache Zeppelin: A web interface for a notebook type UI (much like iPython notebooks). It’s often used to experiment with your Spark scripts (like in the Spark shell) and visualize your big data sets. You can e.g. directly execute SQL queries with SparkSQL, and visualize results in graphs. Other plug-ins (interpreters) include Markdown, Shell scripts, Python, R, Hive, Cassandra DBs, HDFS, etc. It’s nice to experiment, share and document your code during the development process.
-
Hue: Hue is short for “Hadoop User Experience”. It’s developed by Cloudera. It’s the equivalent UI to Ambari on Hortonworks. On Hortonworks, you would use Ambari to manage and query your cluster, and Zeppelin for notebook-type development. On Cloudera, Hue does querying and notebook-type developing, and Cloudera Manager does the managing part.
Along with tools like Spark, Pig, and Hive editors, Hue has a built-in Oozie editor, which allows you to avoid the complicated XML config files.
- Presto: Another alternative. It’s a lot like Drill, but is made by Facebook instead of Apache. Presto (as opposed to Drill) can talk to Cassandra, but cannot talk to mongoDB (but Drill can, again). It’s optimized for OLAP, that is, analytical queries), it’s not meant for lots of fast transactions (OLTP). Facebook, Dropbox, and AirBnB use Presto to query petabytes each day. It also has a very nice looking web interface for monitoring.
Older administrative technologies
Two older technologies that are not really in wide use anymore, but might show up somewhere in a legacy system:
- Ganglia: An old monitoring system developed by UC Berkely. It’s not pretty. It’s supplanted by Ambari, Cloudera Manager, and Grafana today.
- Chukwa: A system for collecting and analyzing logs from your cluster. It’s now replaced by Flume and Kafka, the modern, faster, and more general purpose tools.